随着自动驾驶逐渐在各个产业链环节形成规模,头部企业的相对优势将愈发明显。来自Intel的架构师认为,人工智能、大数据、模拟测试和功能安全设计这四大技术将是决定竞争成败的关键因素。
近日,GCP硅谷专家咨询邀请来自英特尔的两位架构师,解读自动驾驶的技术支柱、决定技术成败的关键细节以及英特尔在自动驾驶方面的部分进展。亿欧智库对分享内容进行了简要整理。
从下面的自动驾驶产业图谱可以看出,目前该产业生态初具规模,在不同供应链环节已有一批企业形成竞争优势,跨产业链整合正成为业内玩家继续扩大优势的策略。以英特尔为例,在继续提供芯片方案的同时,安全设计和5G通信也被纳入到业务当中;Waymo自研完整的自动驾驶解决方案,激光雷达也囊括其中。

回归到技术层面,嘉宾认为,依据和客户接触以及工作的感受,影响自动驾驶能否成功,形成相对优势需要四大关键技术作为支柱:人工智能、大数据、模拟和测试、功能安全设计。从自动驾驶的1级到5级,对以上技术的依赖和要求度将显著提高。
自动驾驶的智能模块
在自动驾驶的智能模块,可以大体分为两部分:感知系统和环境模型、驾驶策略和路径选择。
前者在业界内更被熟知,参与者也相对更多。在利用图像、影像样本进行训练的过程中,神经网络能够发现其中物体的某些特征,通过自我学习实现目标识别。以激光雷达、摄像头等传感器为载体,装载有智能识别的传感器系统使自动驾驶汽车有了“眼睛”。此外,定位系统和高清地图能够与传感器识别结果互相印证,提升感知准确性。多目标跟踪的技术能够跟踪多个目标在一段时间的动作轨迹,解决了感知动态物体的问题。
驾驶策略和路径选择的模块相对门槛更高。系统需要自我规划全局优化的路径,对周边行人和车辆的行为进行判断,据此在可驾驶范围内完成驾驶行为,并能够应付反常现象和紧急情况。
大数据的采集和计算
总的来说,数据的采集、计算和训练是相当费时费力费钱的工作,会给多个研发环节带来冲击,包括自动驾驶数据的录入和存储、数据标注和检索、模型训练,甚至会影响到整个研发模式的进行。
要形成准确性达到上路标准的深度学习模型,需要大量的训练数据和准确标注的训练目标。如果以500万英里的数据需求量和汽车35迈的速度为标准,一辆车要不间断地采集数据49年,或者说50辆车采集数据一整年。硬件方面,数据的采集要满足日后各种各样的算法研发需求,所以采集车应配备最好的传感器。存储和传输方面,一般采样车记录的数据每小时能达到7-15TB(1TB=1024GB),50辆车采集一个月总共将有56PB(1PB=1024TB)空间。更形象一些的话,3个月的数据量需要有两个篮球场大小的场地来存放数据存储硬盘和电源,这样量级的数据要完成拷贝就要花费几天时间。
数据的标注、检索和训练时间同样很长,都严重拖延了研发进度,这是当前自动驾驶研发面临最为严峻的问题之一。不过行业内部对此少有关注。
细节决定成败-模拟驾驶
据估测,自动驾驶汽车需要完成2.75亿英里的测试路程才能证明它对于人类而言足够安全。而模拟驾驶成为路测之外最好的补充手段,能够检验算法在各种人为模拟环境中的表现,减少对实况数据的依赖。
工程师通过变化模拟场景中各个因素的参数,能够突破实际路测场景固定的样本限制,显著提高数据量。还能模拟传感器在老化、失灵等等情况下汽车可能出现的问题,如何处理事故,以及容错系统(指某个子系统坏掉之后其他系统该如何反应)的表现。模拟驾驶为自动驾驶系统每个细节的安全性、可靠性提供了测试机会,一个公司在这方面的投入度将可能决定其成败。
设计决定成败——汽车安全完整性(ASIL)
功能安全是衡量自动驾驶容错性能的指标。ISO26262(针对汽车中特定的电气器件、电子设备、可编程电子器件指定的国际性安全标准)给系统安全的分析和设计提供了标准。其中ASIL等级(Automotive Safety Integration Level,汽车安全完整性等级)用来对系统进行危害分析和风险评估,是验证自动驾驶安全性的重要考核标准。ASIL等级划分依据严重度、暴露率可控性三个维度确定,其中D代表最高等级(最危险),A代表最低等级,QM代表质量管理(按照质量管理体系开发系统或功能就足够,无需考虑安全设计)。
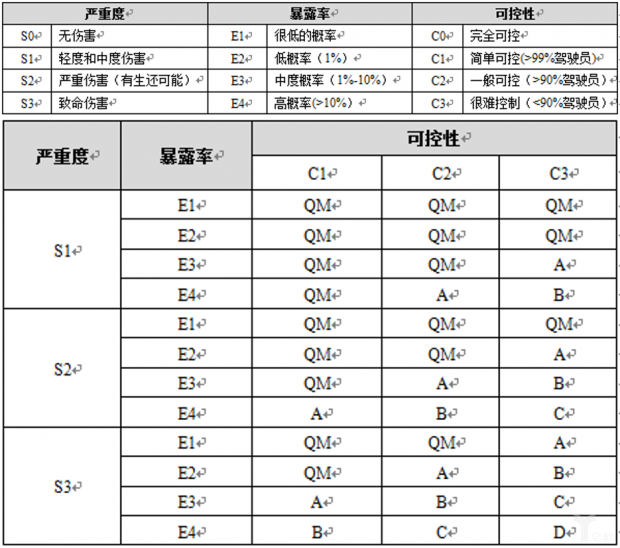
汽车安全设计中,目前有三种选择方案:最简设计中每个子系统没有冗余保障,在系统发生故障后将影响整个自动驾驶系统的运行;冗余设计则增强了子系统的鲁棒性,一旦其中一个损坏依然不影响汽车的正常运作,但同样的两个系统同时运作却得出不同指令的时候,可能会给系统造成困扰;最优方案是择优设计,既提供了冗余安全,也能在子系统指令不同时择取最优方案。
英特尔在自动驾驶的进展
英特尔目前有着基于大数据的一整套自动驾驶开发流程:从收集数据,分类标注,建立数据库,设计和训练模型,验证准确性,优化模型,直到装载在量产车上,英特尔在不同阶段也部署了不同的研发人员和技术能力(包括数据标注人员、数据科学家和软件开发师)。

问答部分
Q:在无人驾驶系统中,有没有识别率更高、训练更高效、终端计算量更好的深度学习方法?
A:算法还在不停改进,训练量大小现在还不是最关心的,所有的厂家最关心的还是检测能力有多高,能发现多少问题,证明系统的可行性。训练得等到将来产品出来的时候才会变得更重要。此外,识别环境这部分的算法很多人都能掌握到,但算法的强弱在第二部分会区分开来,在汽车怎么和别人互动这方面不同企业间的算法能力会有很大区别。
Q:算法研发最大的难度是什么?
A:我感觉是算法需要照顾到方方面面,估计到所有可能的驾驶场景。训练的样本数据需要有代表性,否则输出的结果很难上路。没有数据无法训练。比如,高速上下匝道的并线、环形道并线是比较困难的例子,这些问题现在还没有完全解决。
Q:目前自动驾驶主要的算法路径有哪些?哪些是最优的?
A:自主学习很多人都在谈,但受到数据样本的限制,神经网络可能无法覆盖到更多的场景。因此还需要人为设定规则。此外,汽车的特殊性要求它的驾驶行为必须可解释,以满足政府部门的监管需求和消费者的信任。
Q:数据的传输储存有什么策略吗?
A:现在有个领域,汽车上传非常规的数据到数据中心,用于算法的继续优化,其他日常的数据可能交由本地处理。